
I've been working on systems that need to process massive volumes of data. The kind where calling an LLM API for each item isn't even a conversation, the math just doesn't work.
At production scale, you hit a wall. LLMs are incredible, but they're not built for grinding through millions of requests. So I started thinking differently about the problem.
What to do instead:
Stop trying to make LLMs grind. Use them to teach.
To illustrate this concept, I took CIFAR images of fruit. had Gemini label 1,500 of them for sixty cents (wow), then trained a MobileNet model on those labels.
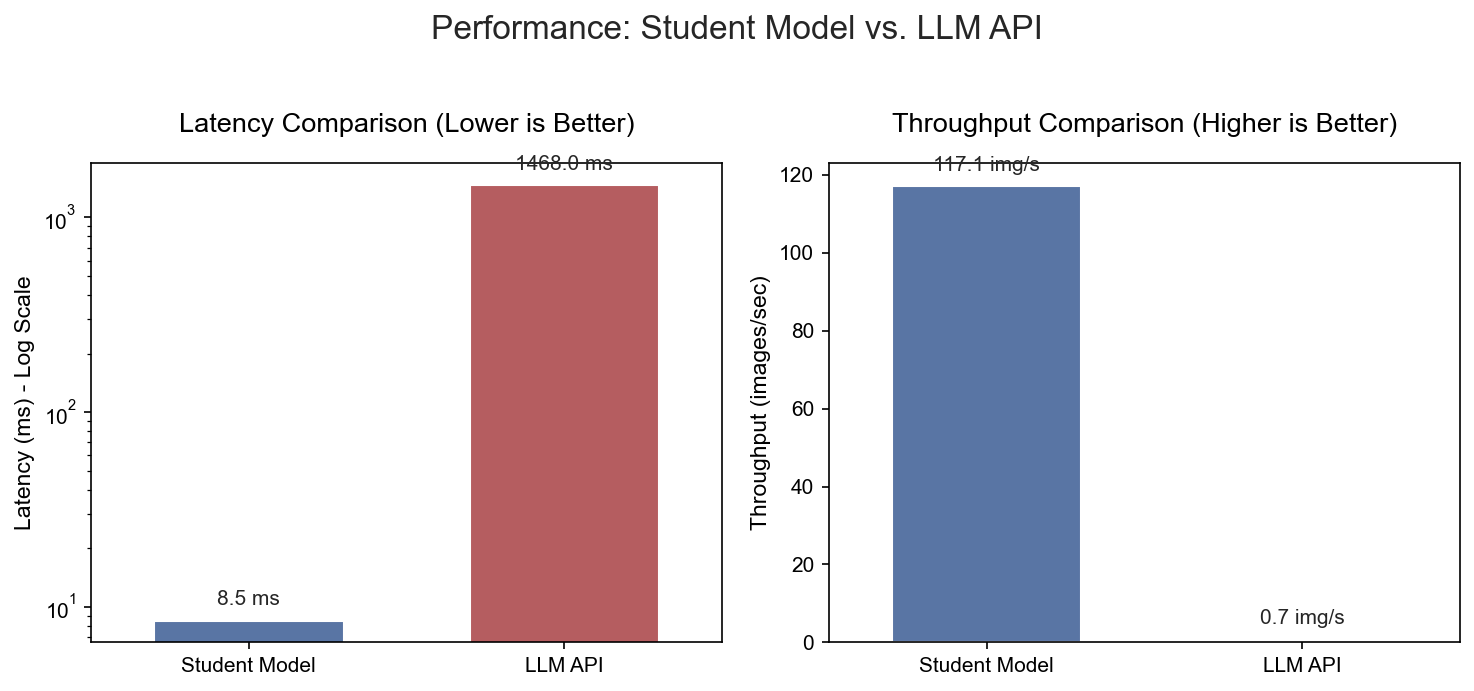
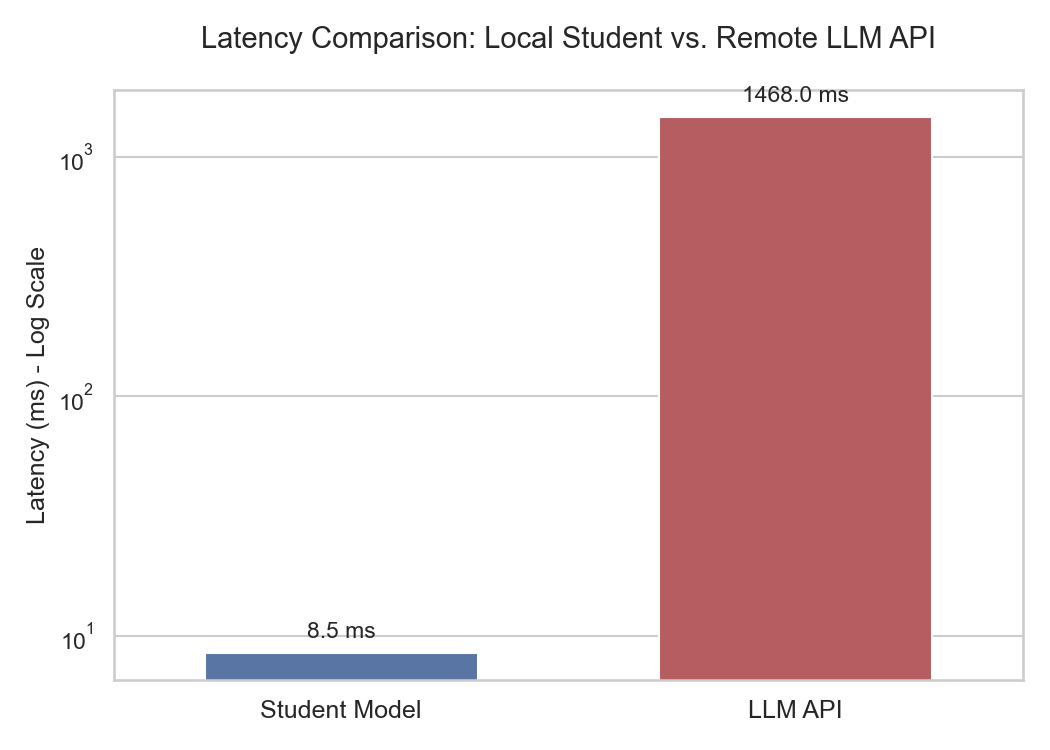
Student model: 8.5ms latency, 117 img/s, 91% accuracy
Gemini API: 1,468ms latency, 0.7 img/s
Result: 172× speed improvement
(All results run on M3 Macbook Pro using Python and PyTorch, nothing fancy)
The student model isn't just fast; it's also accurate. Here's the confusion matrix from the test set, showing strong performance across all five classes.
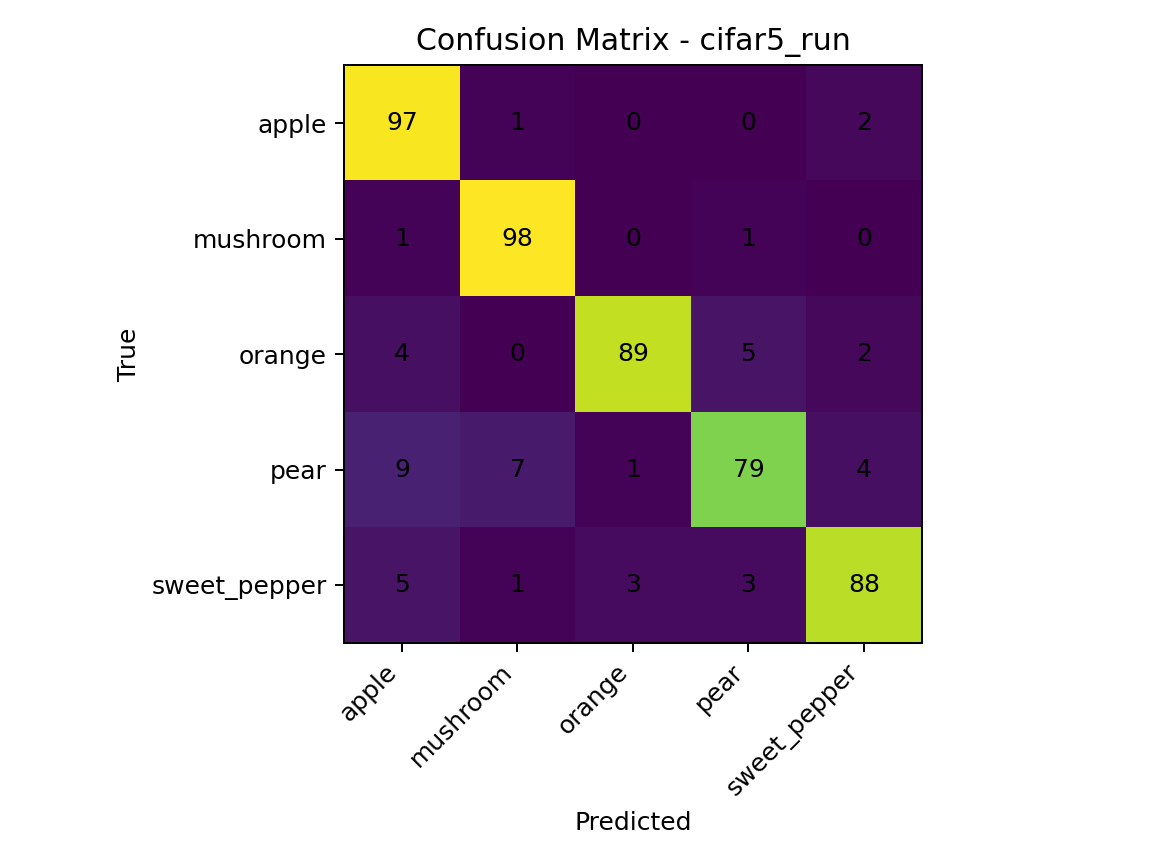
(not shockingly the LLM is most confused by Apples and Pears, pretty similar fruits)
The Architecture Pattern
Here's what I've learned works at scale:
- LLM labels your data (I like to run it through 2x to ensure agreement in each pass)
- Human in the Loop to review and ensure high levels of training data accuracy.
- Train a small model (XGBoost, MobileNet, YOLO) on those labels
- Deploy the small model for production traffic
- Route uncertain cases back to the LLM
- Use those examples to continuously improve your model
The magic happens in step 5. Most requests never need the expensive model.
Confidence-Based Routing
This is where the real "magic" of the flywheel happens. If the student model's confidence is below a certain threshold, escalate to the LLM. Otherwise, trust the local result.
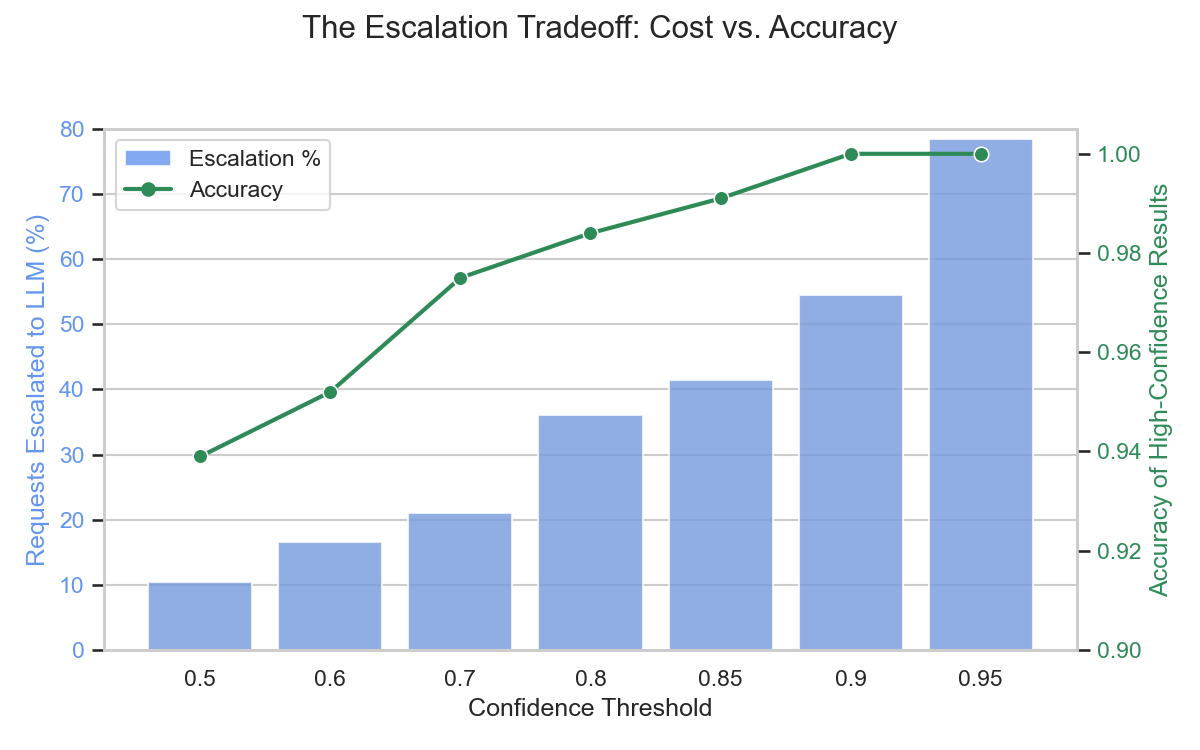
This creates a tunable tradeoff between cost and accuracy, as you demand higher confidence for local predictions (moving right on the chart), the accuracy of those predictions approaches 100%, but you have to escalate a larger percentage of requests to the LLM.
Let's make this concrete. Look at the 0.80 threshold. At this level:
- You only pay the "LLM tax" on 36% of your requests.
- The other 64% are handled locally at 98.4% accuracy.

At a scale of one million items per month, that's the difference between 1,000,000 expensive LLM calls versus just 360,000. This is the core of the flywheel: you get massive cost and speed benefits for the majority of requests, and every escalated request is a high-quality, free training example to make the student model even smarter for the next round.
This creates a flywheel effect. Your model improves by learning from the hardest cases, the ones where it was uncertain or wrong. Retrain and watch your margins grow even larger.
Why This Matters in Production
Performance: 172× faster is time, compute, data savings (your infra engineers will thank you!)
Economics: Even with 10% escalation, you cut inference costs by ~90%.
I've applied variations of this pattern to document processing, content classification, and data extraction. The specific implementation varies, but the architectural principle holds: LLMs excel at creating training data, not serving production traffic.
In Summary
Most production AI systems don't need frontier model intelligence for every single request. (I will say I have faced other ML problems where really ONLY a frontier LLM will do). They need it for the training data and the edge cases.
The confidence threshold creates a system where your expensive model teaches your cheap model, and the cheap model handles the volume. Over time, fewer requests need escalation because the student learns from its mistakes.
That's the flywheel: LLM intelligence at local model speed, continuously improving.
Try It Yourself
I've open-sourced the complete pipeline:
git clone https://github.com/Ryandonofrio3/llm-flywheel
make all
The demo uses toy data, but the pattern scales. I've used this approach successfully on much larger (and harder!) problems.
The code includes the full labeling pipeline, training setup, and benchmarking scripts. Run it and see the difference for yourself.